

AI at Work: Why Data Inputs Matter
AI doesn’t think for you. It thinks with the inputs you craft.

Previously, we talked about problem framing, and how to clearly define your goals and success measures to set the stage for productive AI projects. With that foundation, the next step is to analyze your inputs: the information you give to AI shapes what you get back.
This “input intelligence” applies to both the data you control as well as the data the AI itself has been trained on. Getting smarter on these input data streams turns “let’s see what it gives me” into “let’s get what I actually need.”
Everything is Data Now
We data nerds at We Dig Data have something in common with AI: to us, everything is data.
Numbers and spreadsheets? Of course. But also the meeting notes, PDFs, forms, videos, and policy manuals that exist across your organization. AI systems don’t distinguish between “qualitative” (text) and “quantitative” (numbers) the way humans do. If it can be read, parsed, or summarized, it becomes data.
This is really powerful, but it also carries risks. While it’s tempting to drop everything you have into the AI, the quality, consistency, and clarity of your inputs directly shape whether AI delivers helpful insights or confident nonsense.
The Two Parts of Input Intelligence
Effective AI use means understanding both sides of the data equation:
Your inputs: The data, documents, and context you select and feed into the system.
AI’s inputs: The training data, assumptions, and limits baked into the model.
Good, relevant inputs = good, relevant outputs.
Messy, unreliable inputs = messy, unreliable outputs.
“Input intelligence” doesn’t require advanced data skills. It’s about understanding what you are feeding into the model or tool right from the start, and keeping a pulse on what’s new or changed along the way.
How to Make Your Data AI-Ready
Data rarely starts “AI-ready.” Most of us are working with a mix of formats, systems, and standards that evolved over time. Some of it is tidy and structured, like spreadsheets, forms, and databases. Other data is unstructured, such as emails, PDFs, notes, or images.
First, start with a quick audit:
What data do we actually have, and where does it live?
Who owns it and keeps it updated?
How current, complete and consistent is it?
Once you have compiled this information, take a few practical steps to prepare your data for AI use. Why? Tools need to be able to find, understand and apply your data correctly, using it to build a bridge between accumulated files and usable knowledge.
Add context: Use descriptive titles and lightweight metadata (dates, owners, topics).
Choose wisely: Select data that’s current and representative of your work, not just what’s easy to get.
Structure where you can: Break long documents into logical sections, use consistent headings, and clean up layout noise in PDFs or scans.
Document sources: Note what’s included, where it came from, and how it’s maintained. Submit these notes alongside your documents.
Test early: Try a small sample of your data in a basic AI tool that can summarize text or search your documents. See how well it understands your content. If the AI’s output misses the mark, refine and retry.
If your data has gaps or blind spots - outdated material, missing segments, unrepresented groups - call those out in your documentation and in your instructions to the AI. Clearly defining your data’s limits keeps the AI focused on relevant and higher priority information, producing results that are more accurate and trustworthy.
What to Understand About the AI’s Training Data
Every AI tool is built on a model that’s been “trained” on large datasets, often drawn from public sources or licensed material. Training teaches an AI model by showing it many examples so it can recognize patterns and make predictions on its own. AI models are powerful pattern recognizers, but they make assumptions based on what they’ve seen.
That means:
By default, AI tools don’t know your organization’s data, policies, or context.
Many have a knowledge cutoff - a point in time beyond which they don’t “know” newer events or data.
And like any human system, they reflect the bias in their sources.
Questions to Ask About the AI Model and its Data
When you’re evaluating an AI tool, start by asking what you can about the model behind it. Public models (like ChatGPT, Claude, or Gemini) usually share only general information about their training, such as broad policies and practices, not the exact datasets or how information is weighted.
Enterprise or open-source models may offer a bit more visibility, such as how often they’re updated or how their training data was selected, but full transparency is still rare.
Look for model or system cards that outline the types of data used (public, licensed, or synthetic), the model’s knowledge cutoff date, and any known limitations or bias risks. Some will also describe the benchmarks used to test reasoning and reliability before release.
You may not get complete answers, but asking these questions helps you see where the blind spots are, and plan how to fill them with your own trusted data and context.
Add Your Own Context: Retrieval-Augmented Generation (RAG)
AI gives you an answer drawn from patterns in the data to which it’s been exposed.
To make those results more relevant, many organizations now use Retrieval-Augmented Generation (RAG).
In plain terms: RAG lets you connect AI tools to your own, trusted data, such as internal documents, reports, or databases, so that the model’s responses reflect your world, not just the information pulled from the internet or model’s original training data.
Think of RAG as giving AI access to your organization’s private reference library. It doesn’t retrain the model; it simply grounds the AI’s answers in real, local knowledge. (Could you train a model in local knowledge? Absolutely - but that’s an advanced path, and not where most teams need to start.)
When evaluating an AI tool for use, consider whether you plan to use RAG now or in the future. Does the tool support integration of your own data? What privacy protections for your data exist?
If you’re considering RAG, engage your technical partners early. You’ll want to ask them these questions about the internal data sources that may connect with the AI tool:
Data readiness: Are the sources you’d want to use well organized, consistent, and accessible?
Infrastructure: Do you have the right environment (cloud storage, APIs, or search tools) to connect data securely?
Permissions and privacy: Who owns the data, and do you have clear policies on what can or cannot be exposed to AI systems?
Maintenance: Who ensures the data stays current, and how are updates or removals handled?
Partnership: Do you have the right internal or external technical partners to design, implement, and monitor a RAG setup over time?
These questions reach beyond the AI tool itself; they touch on data governance, infrastructure, and collaboration between technical and program teams. Even if you’re not using RAG yet, having these discussions early helps you build the foundation for a safe, effective implementation later.
Open vs. Closed AI Systems: What You Need to Know
Before feeding any data into AI, it’s critical to understand where that data goes.
Open systems (like public AI tools) may store or reuse your data to improve their models. They’re convenient and trained on broad data, but come with risk.
Closed systems keep data private, often running within your organization’s infrastructure or through vendors that guarantee isolation and no retraining.
Why does this matter?
It defines how much control you retain over what you share.
It has relevance for data security and compliance.
An open or closed system determines how safely you can use AI for different kinds of work. A few rules of thumb:
Never upload confidential or regulated data into an open AI tool, like a personal account of ChatGPT or Claude.
For sensitive or proprietary work, use enterprise or closed systems.
Always check your organization’s AI, data sharing, and software policies.
Always check your vendor’s data use and retention policies.
Examples of Input Intelligence in Action
In a previous post, we discussed how to frame a problem for AI projects. In the below three examples, we demonstrate input intelligence in action: making sure your data and context are ready so that AI outputs are trustworthy and actionable.
Scroll down to download a free Input Intelligence Checklist you can use to evaluate your own data and prepare it for AI tools.
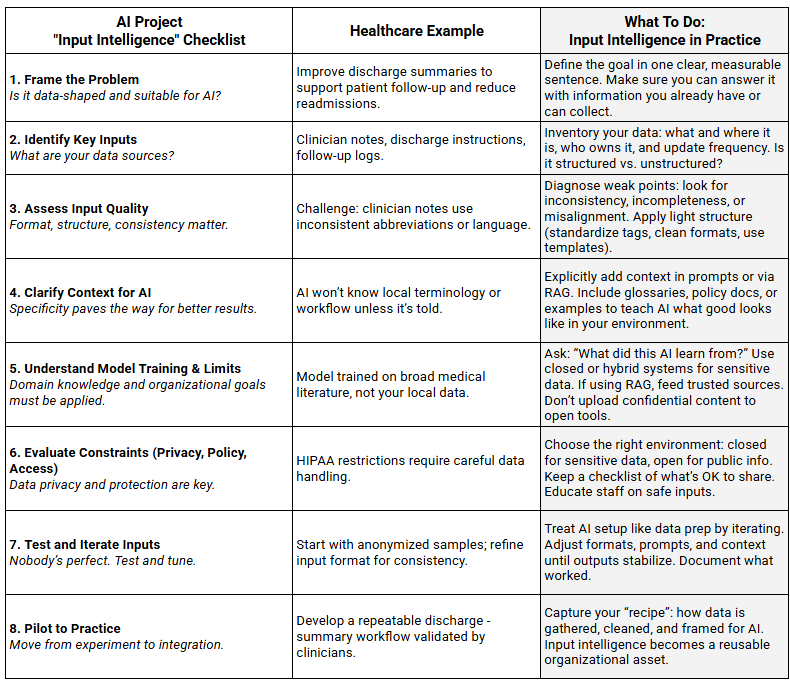
Example 1: Health Care Patient Visit Summaries and Follow Up
In health care, privacy rules and data quality challenges make input intelligence essential for building trustworthy AI workflows.
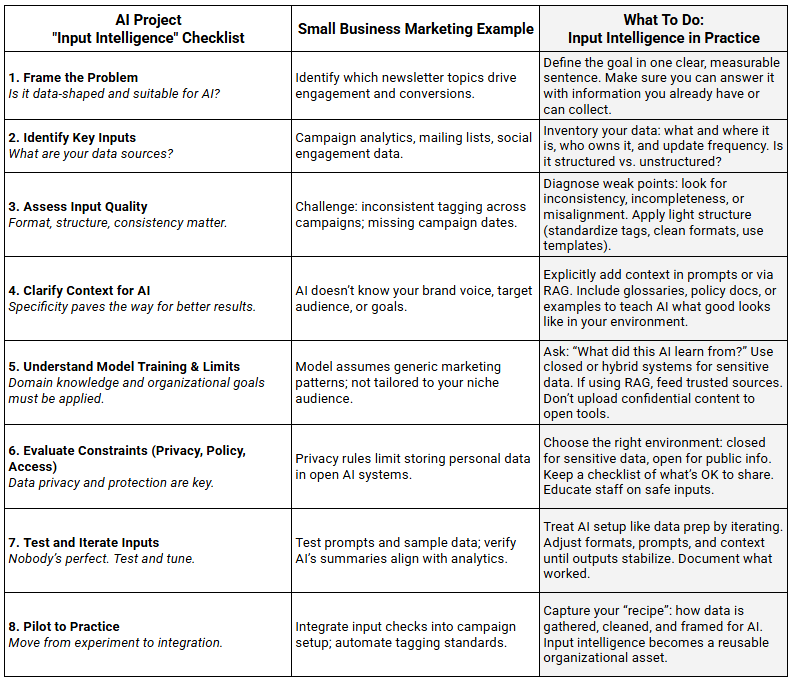
EXAMPLE 2: Marketing Engagement and Conversions
Next, we turn to small business marketing, where consistent, well-structured inputs can mean the difference between useful insights and misleading analytics.
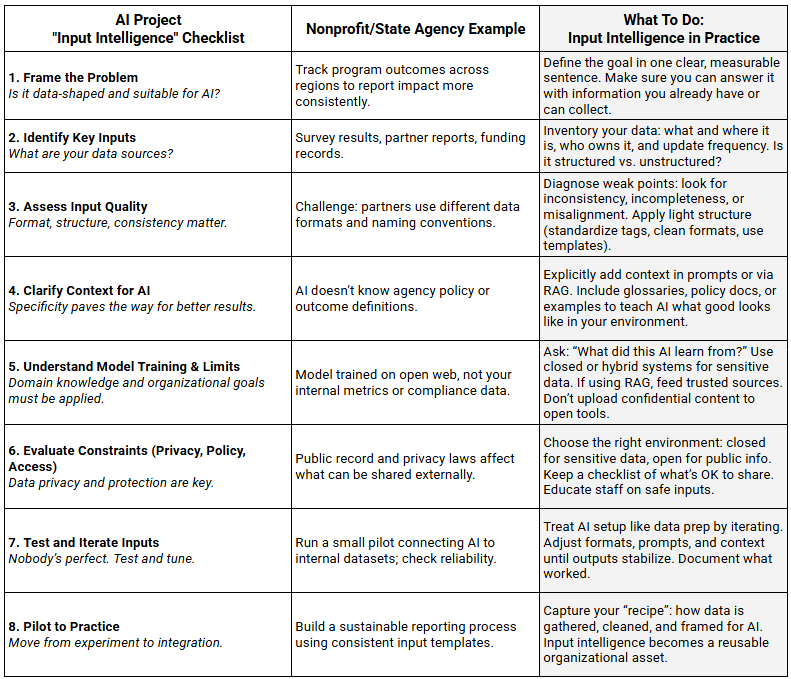
EXAMPLE 3: Nonprofit Program Management and Performance
Finally, let’s look at a nonprofit or state agency setting, where diverse data sources and compliance requirements test how well input intelligence can bring structure and clarity to complex information.
Ready to put these ideas into practice? We’ve created a simple Input Intelligence Checklist to help you apply these steps in your own projects - from auditing your data to choosing the right sources and documenting context.
Input intelligence isn’t about having perfect data. It’s about understanding what you have, how you use it, and what it tells the AI about your work. Input intelligence is a bridge between experimenting with AI and trusting it as part of regular operations.
From Inputs to Insights: Preparing for the Next Step
Strong inputs create reliable outputs. Understanding both your data and the AI’s data gives you the foundation to evaluate and improve what comes out the other side.
Once you’ve done the input intelligence work, you’re ready for the next step of evaluating and refining AI outputs. That’s where experiments become workflows. Look for “AI at Work: Reading the Results,” in which we explore how to assess accuracy, reliability, and bias in AI-generated outputs.
This is the third in a series of five posts focused on AI at Work: practical guidance for moving from AI experimentation to workflow integration. Check out the rest of the AI at Work series: The Human Factor, Frame the Problem, When to Trust, Adapt, or Toss AI Outputs and Translating AI Results into Decisions and Action.
Was this helpful?
Click the ❤️ below. This helps other readers find this content and lets us know what resonates.