

AI at Work: When to Trust, Adapt, or Toss AI Outputs
Before you embed AI into workflows, make sure you can tell which outputs to trust, tweak, or toss.

When teams first start using AI, the results can look impressive — polished, confident, and fast. But confidence isn’t the same as accuracy. Before those outputs make their way into reports, dashboards, or decision workflows, you need a way to tell which ones you can trust, which need a human touch, and which should go straight to the discard pile.
In our earlier posts, we talked about how humans set AI up for success by framing the right problem and preparing the right data inputs. This post focuses on that middle stretch of your AI journey — moving from early experiments to operational use — and building the review habits that keep AI reliable as it scales.
Don’t Mistake Confidence for Accuracy
Early AI wins can feel like magic: you ask a question, and it responds instantly in full sentences. But that polish can be a trap. Even the best-tuned models make confident mistakes. They state guesses as facts, fill gaps with plausible-sounding details, and carry errors forward at speed once outputs start feeding into your systems.
That’s why human review isn’t a temporary phase; it’s part of the quality infrastructure. Even AI companies rely on people to score model outputs for accuracy, bias, and potential harm. You should too.
No matter how advanced the model, only people who understand your context, data, and goals can judge whether an output is fit for purpose. The review stage is where your earlier work — defining goals, shaping prompts, curating inputs — meets reality. It’s where AI can evolve out of an experiment and into how your organization operates.
A Shared Language for Output Review
Without common standards, AI review becomes subjective. A shared framework helps teams speak the same language about quality and next steps.
Keep it simple: Trust - Adapt - Toss. A quick, repeatable way to decide what’s ready to use, what needs editing, and what needs a complete rethink.
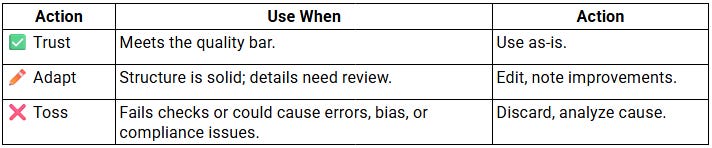
Labeling outputs during testing helps teams find the right balance of automation and oversight. Over time, those labels become signals: where to add checkpoints, when to scale up automation, and how to track improvement.
How to Define “Good Enough”
Once you’ve defined how to label outputs (Trust, Adapt, or Toss), the next question is: what does “good enough” look like?
Different tasks need different levels of accuracy and oversight. A brainstorm can survive a few rough edges. A grant report can’t.
The key is to set thresholds by the task’s purpose and risk, not by the AI tool you’re using.
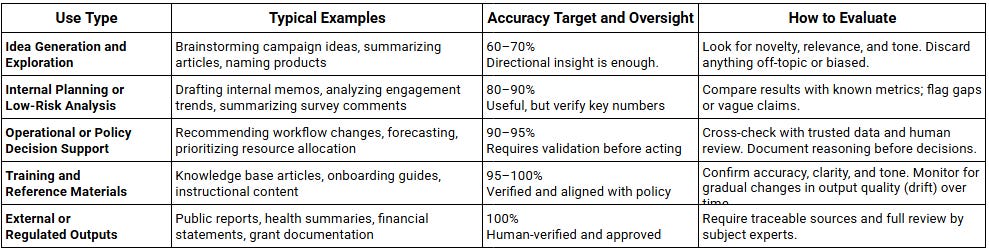
Note that “Internal” doesn’t always mean “low risk.” A patient summary drafted for internal review can still affect care whereas a marketing campaign brief might only guide next week’s social post. The difference is impact, who will act on the output, and what happens if it’s wrong.
Evaluating AI Outputs: When to Trust, Adapt, or Toss
Building on our case studies covered previously in the AI at Work series, here’s how a team might evaluate AI results in practice in three different industries.

Data-Intensive AI? Don’t Go It Alone
When outputs are driven by complex data work (joining data sets, creating new calculated fields or retrieving information from large document collections), partner with your data analyst, data scientist and engineering partners to test like you would a new analytics report or output. Some best practices to follow:
Reviewer of record: Assign one human reviewer per output type to log Trust/Adapt/Toss decisions and rationale.
Change control: Keep a simple log of which model, prompt, and dataset version produced each result.
Automated validators: Build simple checks (automatic checks for missing data, incorrect totals, date errors, or duplicates) before human review.
“Golden” sets: Keep a small sample of verified correct cases to compare versions of your prompts or model setups to see which performs best.
Shadow runs: Let AI and humans work in parallel for a few cycles; compare accuracy and effort.
Holdouts and backtesting: Test on a recent sample you’ve held aside (a ‘holdout set’) to see if results still stand.
The goal is detailed visibility into what’s working and where accuracy slips.
4 Red Flags to Build Into Your Output Review
Whether your AI produces text, summaries, or analysis, the best safeguard is a structured review checklist. These four categories cover most risks - factual, numeric, reasoning and tone - and can be embedded in your human review or automated checks.
1. Data and Numeric Integrity
When outputs rely on numbers, start here. AI can invent or misinterpret numbers with alarming confidence.
Watch for:
Totals or percentages that don’t reconcile.
Unexplained spikes or drops versus historical data.
Calculations that can’t be traced to source figures.
Results that exceed logical limits (e.g., 120% response rate).
Missing uncertainty ranges or confidence intervals.
Quick check: Compare with a trusted “golden” dataset or perform quick common sense checks before accepting results.
2. Factual Accuracy and Source Traceability
Fluent writing isn’t proof of truth. AI often fills gaps with plausible fiction.
Watch for:
Names of people, organizations, or laws that don’t exist.
Real entities cited inaccurately (wrong dates, authors, agencies).
“Phantom” citations or references that don’t exist.
Generic phrasing like “experts say” with no source.
Quick check: Verify all names, titles, and references against internal or public databases. If you can’t see where the information came from, you can’t trust it. Even workflows grounded in your specific context and internal documents and datasets can produce these issues. The AI tool should be able to provide sourcing for any contributing material.
3. Reasoning and Logic Quality
Really read and digest the content, don’t just scan the output as a check. Good outputs show their work; weak ones skip the middle steps.
Watch for:
Unsupported conclusions or circular logic.
Contradictions between summaries and supporting points.
Explanations that restate the question without analysis.
Recommendations that ignore evidence.
Quick check: Ask AI to explain how it reached the answer. Does the reasoning feel shallow, circular or is it missing? It’s time for human review.
Next step: When in doubt, test twice: once for correctness, once for consistency. AI should pass both before it moves into your workflow.
4. Context, Policy, and Tone Alignment
AI doesn’t automatically understand your organization’s boundaries, audience, or voice.
Watch for:
Misuse of domain-specific terms.
Recommendations that breach compliance or policy.
Outputs that ignore local or regulatory context.
Mismatch in tone or sensitivity (e.g., clinical vs. public language).
Quick check: Maintain a package of context such as key policies, glossaries, and examples of approved language that ground your prompts and reduce drift.
Takeaway: A consistent checklist turns “gut feel” review into measurable quality control. Red flags aren’t just problems to catch - they’re signals to improve prompts, inputs, and model choice upstream.
From Evaluation to Continuous Improvement
Evaluating outputs isn’t a one-time check. It’s a process by which experimentation becomes reliable, repeatable work.
Once you’ve defined what “good enough” looks like, you can start using those thresholds to decide when an experiment is ready to move into production and how to keep it healthy once it’s there.
When to Move From Experiment to Go-Live
When an AI process consistently meets your thresholds across multiple iterations, it’s a candidate for integration. Before you promote it, confirm:
Consistency: The AI process produces stable results on your golden test set.
Coverage: It performs well on typical cases, not just best-case scenarios.
Confidence: The team reviewing it agrees the AI process is a fit for its intended purpose.
Building Your Feedback Loop
Once you take the AI process live, your focus will shift from proving it works to keeping it working. That’s where your feedback loop takes over.
Log results: Track each output with its task type (brainstorming, analytics, etc.), model and version, data snapshot, and your decision (✅ Trust / ✏️ Adapt / ❌ Toss).
Fix upstream: If you keep editing the same kinds of issues, the problem is happening earlier such as in the prompt, the data, or the examples. Turn recurring “Adapt” edits into upstream rules or prompt tweaks.
Raise the bar: As outputs stabilize, tighten accuracy thresholds or reduce manual review for low-risk tasks.
Monitor updates: Model and data updates can change results. Automate rechecks on your golden set and alert reviewers when accuracy or tone shifts.
Over time, reviews evolve into a continuous improvement system that drives serious impact.
Stay Alert for Performance Drift
Even a strong process can slide over time. Models evolve, data changes, and prompts quietly shift the quality of the output. Watch for early signs of drift like:
The same prompt produces noticeably different results.
Accuracy declines on golden test cases.
Outputs start echoing your input wording or agreeing uncritically.
Quick check: Plan to re-run baseline prompts regularly and log differences in tone, accuracy, and consistency. If the results start to fluctuate, recalibrate before errors multiply.
Why the Output Review Process Matters
AI doesn’t make your organization smarter - your output review process does. When teams document decisions, learn from every “Adapt,” and analyze every “Toss,” they build shared judgment that scales better than any model.
AI can generate words and numbers, but not wisdom. Wisdom comes from people and can be structured, documented, and shared.
Knowing when to trust, adapt, or toss, and building a repeatable review process is how teams turn AI experiments into reliable, high-impact tools at work.
Once you know which outputs you can trust, the next challenge is translating them into insight others can understand and act on - that’s where we’ll go next.
This is the fourth in a series of five posts focused on AI at Work: practical guidance for moving from AI experimentation to workflow integration. Check out the rest of the series: The Human Factor, Frame the Problem, Why Data Inputs Matter, When to Trust, Adapt, or Toss AI Outputs, and Translating AI Results into Decisions and Action.
Please tap the ❤️ at the top or bottom of this post to help others find We Dig Data—your support means a lot!
This is useful. a lot of teams move from ‘it works’ straight to ‘let’s use it’, and skip this layer.
and that’s usually where things break - not in the model, but in how outputs get trusted and used in real workflows.